Chapter 22 Twitter API
You will need to install the following packages for this chapter (run the code):
# install.packages('pacman')
library(pacman)
p_load('httr', 'academictwitteR',
'tidyverse', 'lubridate', 'tidyverse', 'lubridate', 'dplyr', 'rtweet')22.1 Provided services/data
- What data/service is provided by the API?
The API is provided by Twitter. As of 2021, there are 5 different tracks of API: Standard (v1.1), Premium (v1.1), Essential (v2), Elevated (v2), and Academic Research (v2). They offer different data as well as cost differently. For academic research, one should use Standard (v1.1) or Academic Research (v2). I recommend using Academic Research (v2) track, not least because v1.1 is very restrictive for academic research and the version is now in maintenance mode (i.e. it will soon be deprecated). If one still wants to use the Standard track v1.1, please see the addendum below.
Academic Research Track provides the following data access
- Full archive search of tweets
- Tweet counts
- User lookup
- Compliance check (e.g. whether a tweet has been deleted by Twitter)
and many other.
22.2 Prerequisites
- What are the prerequisites to access the API (authentication)?
One needs to have a Twitter account. To obtain Academic Research access, one needs to apply it from here. In the application, one will need to provide a research profile (e.g. Google Scholar profile or a link to the profile in the student directory) and a short description about the research project that would be done with the data obtained through the API. Twitter will then review the application and grant the access if appropriate. For undergraduate students without a research profile, Twitter might ask for endorsement from academic supervisors.
With the granted access, a bearer token is available from the dashboard of the developer portal. For more information about the entire process, please read this vignette of academictwitteR.
It is recommended to set the bearer token as the environment variable TWITTER_BEARER. Please consult Chapter 2 on how to do that in the section on Environment Variables replacing MYSECRET=ROMANCE in the example with TWITTER_BEARER=YourBearerToken.
22.3 Simple API call
- What does a simple API call look like?
The documentation of the API is available here. The bearer token obtained from Twitter should be supplied as an HTTP header preceding with “Bearer”, i.e.
For using the full archive search and tweet counts endpoints, one needs to build a search query first. For example, to search for all German tweets with the hashtags “#ichbinhanna” or “#ichwarhanna”, the query looks like so: #ichbinhanna OR #ichwarhanna lang:DE.
To make a call using httr to obtain tweets matched the above query from 2021-01-01 to 2021-07-31
library(httr)
my_query <- "#ichbinhanna OR #ichwarhanna lang:DE"
endpoint_url <- "https://api.twitter.com/2/tweets/search/all"
params <- list(
"query" = my_query,
"start_time" = "2021-01-01T00:00:00Z",
"end_time" = "2021-07-31T23:59:59Z",
"max_results" = 500
)
r <- httr::GET(url = endpoint_url,
httr::add_headers(
Authorization = paste0("bearer ", Sys.getenv("TWITTER_BEARER"))),
query = params)
httr::content(r)If one is simply interested in the time series data, just make a simply change to the endpoint and some parameters.
params <- list(
"query" = my_query,
"start_time" = "2021-01-01T00:00:00Z",
"end_time" = "2021-07-31T23:59:59Z",
"granularity" = "day" ## obtain a daily time series
)
endpoint_url <- "https://api.twitter.com/2/tweets/counts/all"
r <- httr::GET(url = endpoint_url,
httr::add_headers(
Authorization = paste0("bearer ", Sys.getenv("TWITTER_BEARER"))),
query = params)
httr::content(r)22.4 API access in R
- How can we access the API from R (httr + other packages)?
The package academictwitteR (Barrie and Ho 2021) can be used to access the Academic Research Track. In the following example, the analysis by Haßler et al. (2021) is reproduced. The research question is: How has the number of tweets published with the hashtag #fridaysforfuture been affected by the lockdowns? (See time series in the Figure 3 of the paper) The study period is 2019-06-01 to 2020-05-31 and restricted to only German tweets. The original analysis was done with the v1.1 API. But one can get a better dataset with the Academic Research Track.
academictwitteR looks for the environment variable TWITTER_BEARER for the bearer token. To collect the time series data, we use the count_all_tweets() function.
library(academictwitteR)
library(tidyverse)
library(lubridate)
fff_ts <- count_all_tweets(query = "#fridaysforfuture lang:DE",
start_tweets = "2019-06-01T00:00:00Z",
end_tweets = "2020-05-31T00:00:00Z",
granularity = "day",
n = Inf)
head(fff_ts) # the data is in reverse chronological order## end start tweet_count
## 1 2020-05-01T00:00:00.000Z 2020-04-30T00:00:00.000Z 366
## 2 2020-05-02T00:00:00.000Z 2020-05-01T00:00:00.000Z 345
## 3 2020-05-03T00:00:00.000Z 2020-05-02T00:00:00.000Z 407
## 4 2020-05-04T00:00:00.000Z 2020-05-03T00:00:00.000Z 244
## 5 2020-05-05T00:00:00.000Z 2020-05-04T00:00:00.000Z 465
## 6 2020-05-06T00:00:00.000Z 2020-05-05T00:00:00.000Z 483The daily time series of number of German tweets tweets is displayed in Figure below. However, this is not a perfect replication of the original Figure 3. It is because the original Figure only considers Fridays. 15 The Figure below is an “enhanced remake”.
library(dplyr)
lockdown_date <- as.POSIXct(as.Date("2020-03-23"))
fff_ts %>% mutate(start = ymd_hms(start)) %>% select(start, tweet_count) %>%
ggplot(aes(x = start, y = tweet_count)) + geom_line() +
geom_vline(xintercept = lockdown_date, color = "red", lty = 2) +
xlab("Date") + ylab("Number of German #fridaysforfuture tweets")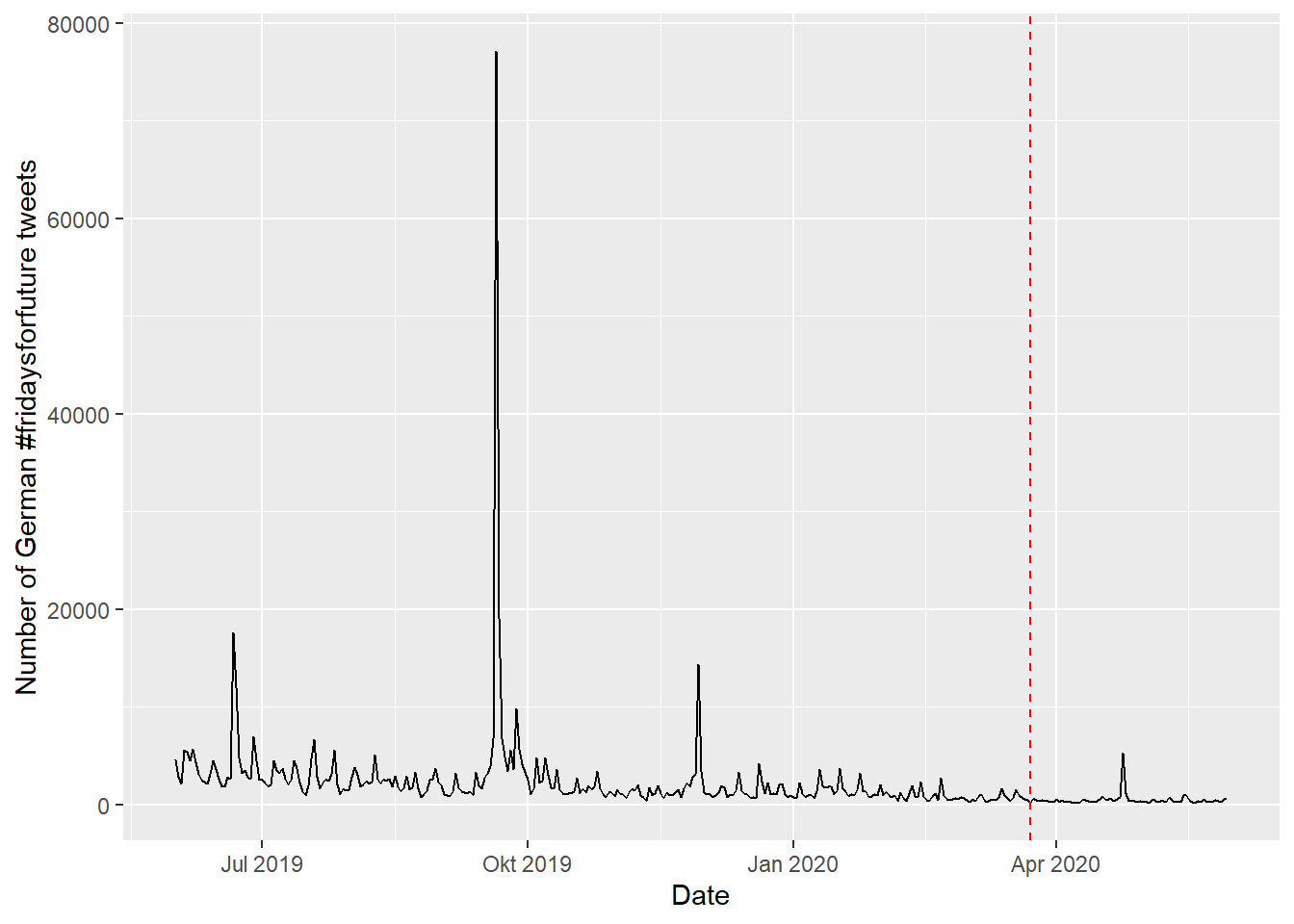
22.6 Addendum: Twitter v1.1
The Standard Track of Twitter v1.1 API is still available and probably will still be available in the near future. If one for any reason doesn’t want to — or cannot — use the Academic Research Track, Twitter v1.1 API is still accessible using the R package rtweet (Kearney 2019).
The access is relatively easy because in most cases, one only needs to have a Twitter account. Before making any actual query, rtweet will do the OAuth authentication automatically 16.
To “replicate” the #ichbinhanna query above:
However, this is not a replication. It is because the Twitter v1.1 API can only be used to search for tweets published in the last few days, whereas Academic Research Track supports full historical search. If one wants to collect a complete historical archive of tweets with v1.1, continuous collection of tweets is needed.
References
To truly answer the research question, I recommend using time series causal inference techniques such as Google’s CausalImpact.↩︎
The authentication information will be stored by default to the hidden file
.rtweet_token.rdsin home directory.↩︎
22.5 Social science examples
There are so many (if not too many) social science research examples using this API. Twitter data have been used for network analysis, text analysis, time series analysis, just to name a few. If one is really interested in examples using the API, on Google Scholar there are around 1,720,000 results (as of writing).
Some scholars link the abundance of papers using Twitter data to the relative openness of the API. Burgess and Bruns (2015) label these Twitter data as “Easy Data”. This massive overrepresentation of easy Twitter data in the literature draws criticism from some social scientists, especially communication scholars. Matamoros-Fernández and Farkas (2021), for example, see this as problematic and the overrepresentation of Twitter in the literature “mak[es] all other platforms seem marginal.” (p. 215) Ironically, in many countries the use of Twitter is marginal. According to the Digital News Report (Newman et al. 2021), only 12% of the German population uses Twitter, which is much less than YouTube (58%), Facebook (44%), Instagram (29%), and even Pinterest (16%).
I recommend thinking thoroughly whether the easy Twitter data are really suitable for answering one’s research questions. If Twitter data are really needed to use, consider also alternative data sources for comparison if possible (e.g. Rauchfleisch, Siegen, and Vogler 2021).