Tuning models
Chapter last updated: 14 Februar 2025
Learning outcomes/objective: Learn…
- …what tuning means.
- …how to tune models using tidymodels.
- …how to tune a random forest/a ridge regression/a lasso.
Source(s): Closely based on superbe summary in Arnold et al. (2024) (check out their research); Tune model parameters
1 Why care about hyperparameters?
- Aim of ML: Find a model that generalizes well from training data to new, unseen data
- Reminder: We evaluate the model using unseen test data, and then usually want to predict outcomes of further unseen data
- Hyperparameters determine a model’s capacity to generalize and may critically affect a model’s performance
- Arnold et al. (2024, 1) find that among 64 machine learning-related political science papers1…
- 36 publications (56.25 %) do not report the values of their hyper- parameters
- 49 publications (76.56 %) do not share information their usage of tuning to find good hyperparameters
- 13 publications (20.31 %) offer a complete account of hyperparameters/tuning
2 What are hyperparameters and why do they need to be tuned?
- Many machine learning models have parameters and also hyperparameters
- Model parameters are learned during training
- Hyperparameters typically set before training
- Determine what a model can learn and how well the model will perform on out-of-sample data (set at meta-level)
- Anything part of the function that maps the data to a performance measure and that can be set to different values can be considered a hyperparameter, e.g., number of trees in a random forest
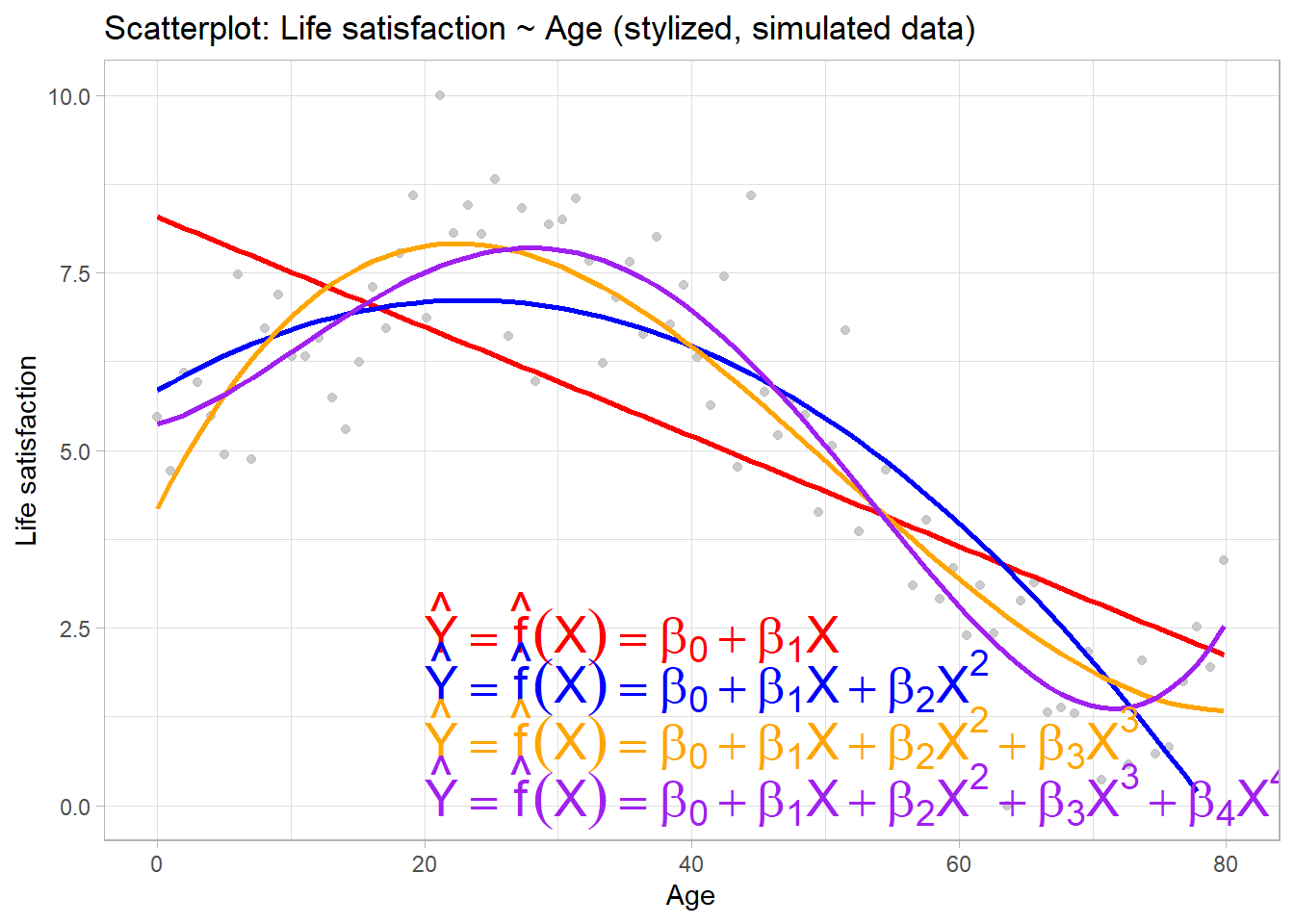
3 Hyperparameters stylized example: Polynomial regression (1)
Parameters are variables that belong to the model itself (here regression coefficients)
Hyperparameters are variables that help specify exact model
Linear regression approach could model relationship between \(X\) and \(Y\) as \(\hat{Y}=\beta_{0} + \beta_{1}X\)
- More flexible model would include additional polynomials in X
Polynomial regression comes with both parameters and hyperparameters (see Figure 1)
- Choosing \(\lambda=2\) \(\rightarrow\) belief that \(Y\) is best predicted by a quadratic function of \(X\), i.e., \(\hat{Y}=\beta_{0} + \beta_{1}X + \beta_{2}X^{2}\)
- Here the hyperparameter \(\lambda\) determines how many parameters (\(\beta\)s) are learned
But we could also rely on data to find optimal value of \(\lambda\)
- Estimate models with different \(\lambda\)’s, evaluate accuracy using MSE and pick best \(\lambda\)
4 Hyperparameters stylized example: Polynomial regression (2)
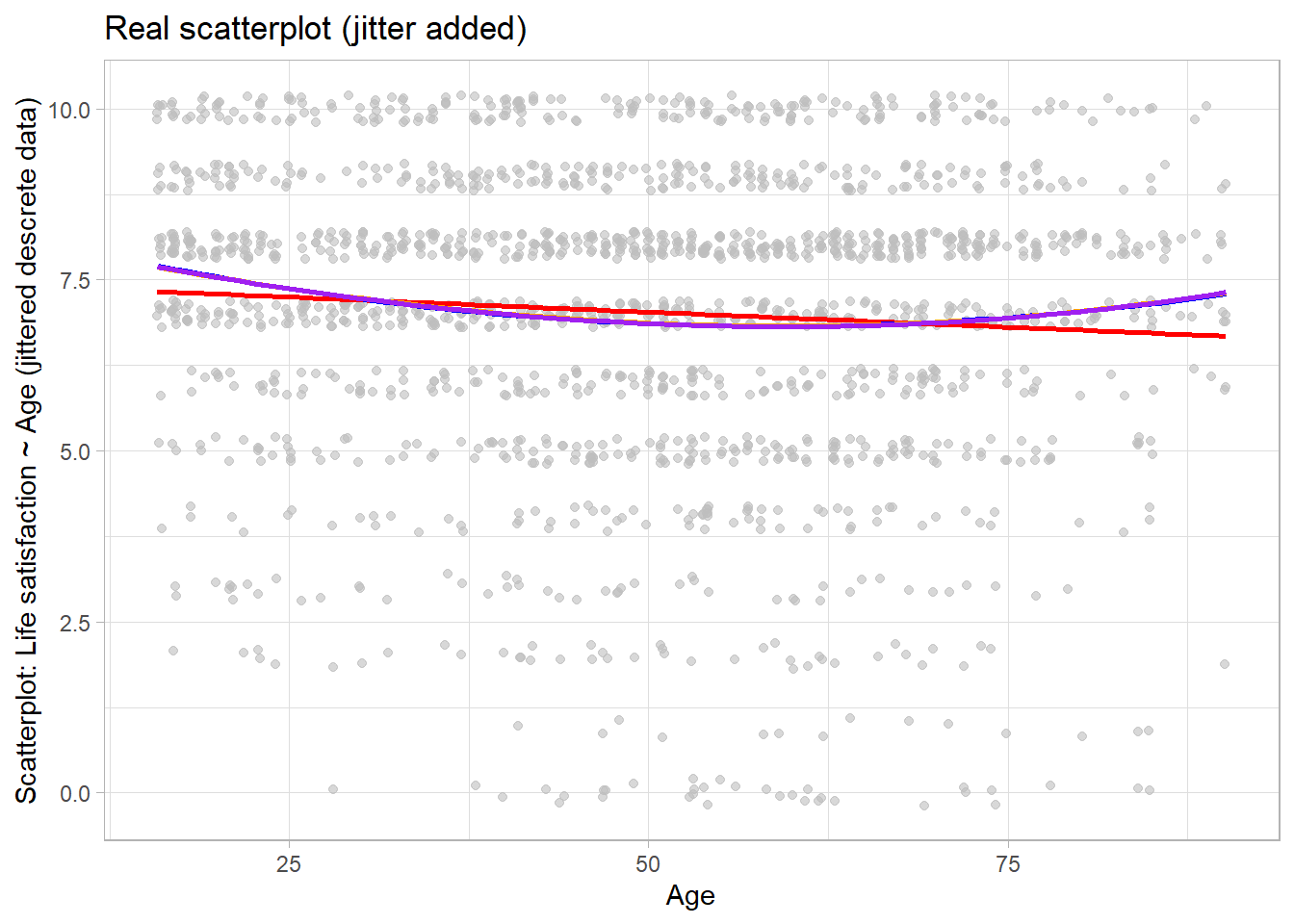
5 The “real” Age-Life satisfaction relationship
Figure 2 illustrates that real relationships seldom follow the nice shape depicted in Figure 1.
6 Steps in tuning (Arnold et al. 2024)
- Understanding the model: What are the available hyperparameters? How do they affect the model?
- Choosing a performance measure: What is a good performance for the machine learning model? (e.g., MSE, MAE, F-1)
- Defining a sensible search space:
- Useful starting points: hyperparameter default values in software libraries, recommendations from the literature, or own previous experience
- Finding the best combination in the search space:
- Grid search: try every possible combination of hyperparameters of the search space to find optimal combination
- Random search: each run picks a different random set of hyperparameters from the search space
- Tuning under strong resource constraints: If model training is computationally demanding, adaptive approaches such as sequential model-based Bayesian optimization allow for efficiently identifying and testing promising hyperparameter candidates.
- Important: Describe whether/how hyperparameters were tuned and final values chosen paper/appendix
7 Models and their hyperparameters
7.1 Lasso & ridge regression
- See
?details_linear_reg_glmnetfor details forglmnetpackage - These models have 2 tuning parameters
penalty: Amount of Regularization (default: see below)2- The
penaltyparameter has no default and requires a single numeric value
- The
mixture: Proportion of Lasso Penalty (default: 1)- A value of
mixture = 1↑ pure lasso model, whilemixture = 0↑ ridge regression; Between 0 and 1 ↑ combination of Lasso and Ridge
- A value of
7.2 Random forest
- See
?details_rand_forest_rangerfor details forrangerpackage - Can be used for both classification and regression
# = number of- Model has 8 tuning (hyper-)parameters
mtry: # Randomly Selected Predictors at split (default: depends on number of columns)trees: # Trees (default: 500)min_n: Minimal Node Sizemin_ndefault depends on the mode (5for regression &10for classification)
7.3 XGBoost tuning parameters (skip)
- See
?details_boost_tree_xgboostfor details forxgboostpackage - Can be used for both classification and regression
# = number of- Model has 8 tuning (hyper-)parameters
tree_depth: Tree depth (default: 6)3trees: # trees (default: 15)4learn_rate: Learning rate (default: 0.3)5- Picking lower value might be better but is slower
mtry: # randomly selected predictors among which splitting candidate is picked (default: see below)min_n: Minimal node size before stopping splitting (default: 1)loss_reduction: Minimum loss reduction (default: 0.0)6sample_size: Proportion observations sampled (default: 1.0)7stop_iter: # iterations before stopping (default: Inf)8
8 Lab: Tuning a random forest
Here, we will simply re-use Step 1 and Step 2 from the corresponding random forest lab.
# Extract data with missing outcome
data_missing_outcome <- data %>% filter(is.na(life_satisfaction))
dim(data_missing_outcome)[1] 205 346# Omit individuals with missing outcome from data
data <- data %>% drop_na(life_satisfaction) # ?drop_na
dim(data)[1] 1772 346# STEP 2
# Split the data into training and test data
data_split <- initial_split(data, prop = 0.80)
data_split # Inspect<Training/Testing/Total>
<1417/355/1772> # Extract the two datasets
data_train <- training(data_split)
data_test <- testing(data_split) # Do not touch until the end!
# Create resampled partitions
set.seed(345)
data_folds <- vfold_cv(data_train, v = 2) # V-fold/k-fold cross-validation
data_folds # data_folds now contains several resamples of our training data # 2-fold cross-validation
# A tibble: 2 × 2
splits id
<list> <chr>
1 <split [708/709]> Fold1
2 <split [709/708]> Fold28.1 Step 3: Specify recipe, model, workflow and tuning parameters
Similar to ridge or lasso regression a random forest has parameters that we can try to tune. Below, we create a model specification for a RF where we will tune…
mtrythe number of predictors to sample at each split andmin_nthe number of observations needed in each resulting node to keep splitting.
Insights: What is mtry and min_n?
- Number of Predictors to Sample at Each Split (
mtry): This hyperparameter controls the number of predictors randomly sampled at each split in the decision tree building process. A smaller value ofmtrycan lead to less correlation between individual trees in the forest, potentially reducing overfitting, but it may also increase the randomness in the model. Conversely, a larger value ofmtrycan lead to stronger individual trees but might increase the risk of overfitting. Typically, you can try different values ofmtryand choose the one that provides the best performance based on cross-validation or other evaluation methods. - Minimum Number of Observations in Each Node (
min_n): This hyperparameter determines the minimum number of observations required in a node for it to be eligible for further splitting. If a node has fewer thanmin_nobservations, it won’t be split further, effectively controlling the depth and complexity of the trees. Setting a higher value ofmin_ncan help prevent overfitting by creating simpler trees, but it may also lead to underfittingif set too high.
These are hyperparameters that can’t be learned from data when training the model. (cf. Source)
# Define recipe
recipe_rf <-
recipe(formula = life_satisfaction ~ ., data = data_train) %>%
update_role(respondent_id, new_role = "ID") %>%
step_filter_missing(all_predictors(), threshold = 0.01) %>%
step_impute_mean(all_numeric_predictors()) %>%
step_unknown(all_nominal_predictors()) %>%
step_nzv(all_predictors()) %>% # remove variables with zero variances
step_novel(all_nominal_predictors()) %>% # prepares data to handle previously unseen factor levels
#step_dummy(all_nominal_predictors()) %>% # dummy codes categorical variables
step_zv(all_predictors()) #%>% # remove vars with only single value
#step_normalize(all_predictors()) # normale predictors
# Inspect the recipe
recipe_rf
# Specify model with tuning
model_rf <- rand_forest(
mtry = tune(), # tune mtry parameter (number of predictors to sample at each split)
trees = 500, # grow 500 trees
min_n = tune() # tune min_n parameter (min N in Node to split)
) %>%
set_mode("regression") %>%
set_engine("ranger",
importance = "permutation") # potentially computational intensive
# Specify workflow (with tuning)
workflow1 <- workflow() %>%
add_recipe(recipe_rf) %>%
add_model(model_rf)8.2 Step 4: Tune, evaluate the model using resampling and choose/explore the best model
8.2.1 Tune, evaluate the model using resampling
Below we use tune_grid() to compute performance metrics (e.g. accuracy or RMSE) for pre-defined set of tuning parameters that correspond to a model or recipe across one or more resamples of the data (below 10 stored in data_folds).
# Specify to use parallel processing
doParallel::registerDoParallel()
set.seed(345)
tune_result <- tune_grid(
workflow1,
resamples = data_folds,
grid = 10, # choose 10 grid points automatically
metrics = metric_set(rmse, rsq, mae)
)
tune_result# Tuning results
# 2-fold cross-validation
# A tibble: 2 × 4
splits id .metrics .notes
<list> <chr> <list> <list>
1 <split [708/709]> Fold1 <tibble [30 × 6]> <tibble [0 × 3]>
2 <split [709/708]> Fold2 <tibble [30 × 6]> <tibble [1 × 3]>
There were issues with some computations:
- Warning(s) x1: 77 columns were requested but there were 76 predictors in the dat...
Run `show_notes(.Last.tune.result)` for more information.
Visualizing the results helps us to evaluate the tuning results. Figure 3 indicates that higher values of min_n and lower values of mtry seem to work better in terms of accuracy.
tune_result %>%
collect_metrics() %>% # extract metrics
filter(.metric == "rmse") %>% # keep rmse only
select(mean, min_n, mtry) %>% # subset variables
pivot_longer(min_n:mtry, # convert to longer
values_to = "value",
names_to = "parameter"
) %>%
ggplot(aes(value, mean, color = parameter)) + # plot!
geom_point(show.legend = FALSE) +
facet_wrap(~parameter, scales = "free_x") +
labs(x = NULL, y = "RMSE")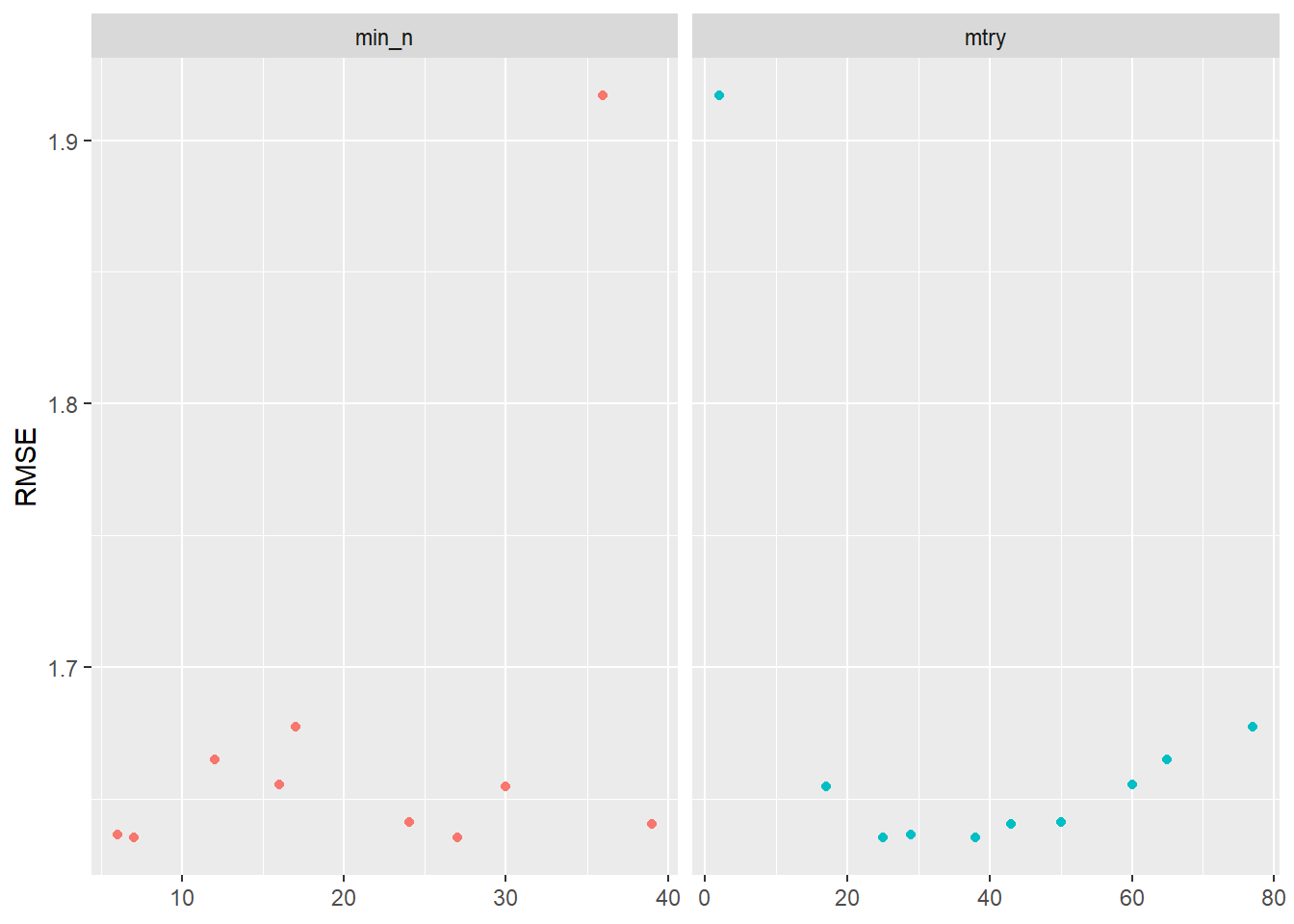
After getting this first glimpse in Figure 3 we might want to make further changes to the grid values that we use for tuning. Below we pick ranges that turned out to be better in Figure 3:
grid1 <- grid_regular(
mtry(range = c(0, 5)), # define range for mtry
min_n(range = c(30, 40)), # define range for min_n
levels = 4 # number of values of each parameter to use to make the regular grid
)
grid1# A tibble: 16 × 2
mtry min_n
<int> <int>
1 0 30
2 1 30
3 3 30
4 5 30
5 0 33
6 1 33
7 3 33
8 5 33
9 0 36
10 1 36
11 3 36
12 5 36
13 0 40
14 1 40
15 3 40
16 5 40Then we re-do the tuning using those values:
set.seed(456)
tune_result2 <- tune_grid(
workflow1,
resamples = data_folds,
grid = grid1
)
tune_result2# Tuning results
# 2-fold cross-validation
# A tibble: 2 × 4
splits id .metrics .notes
<list> <chr> <list> <list>
1 <split [708/709]> Fold1 <tibble [32 × 6]> <tibble [0 × 3]>
2 <split [709/708]> Fold2 <tibble [32 × 6]> <tibble [0 × 3]>Again we visualize the results in Figure 4:
tune_result2 %>%
collect_metrics() %>%
filter(.metric == "rmse") %>%
select(mean, min_n, mtry) %>%
pivot_longer(min_n:mtry,
values_to = "value",
names_to = "parameter"
) %>%
ggplot(aes(value, mean, color = parameter)) +
geom_point(show.legend = FALSE) +
facet_wrap(~parameter, scales = "free_x") +
labs(x = NULL, y = "RMSE")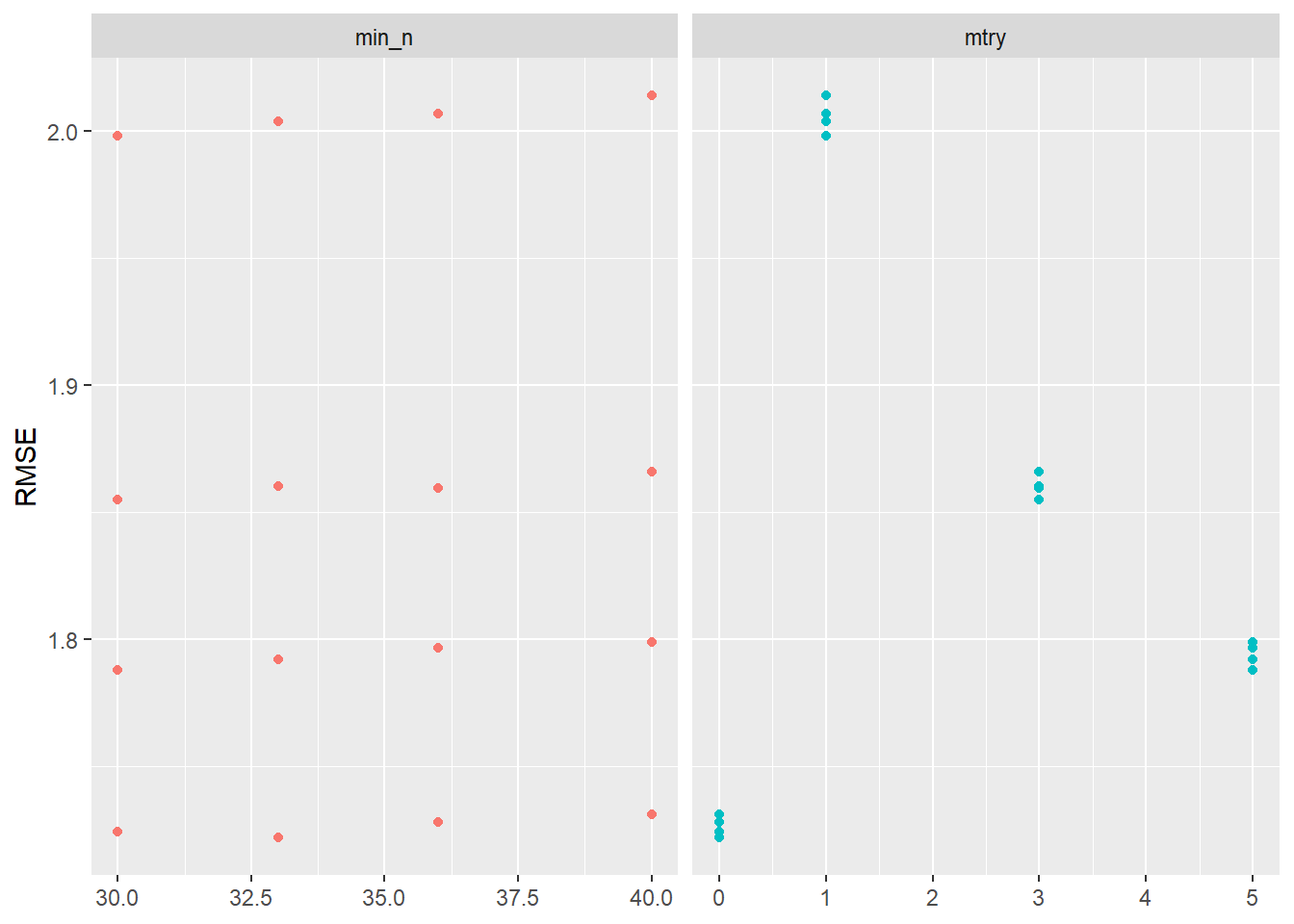
8.2.2 Choose best model after tuning
Choosing the best model, i.e., the model with the best parameter choices obtained in the tuning above (tune_result2), can be done with the select_best() function. After having selected the best parameter values, we update our original model specification stored in model_rf using the finalize_model() function.
# Find tuning parameter combination with best performance values
best_hyperparameters <- select_best(tune_result2, metric = "rmse")
# Take list/tibble of tuning parameter values
# and update model_rf with those values.
model_rf_tuned <- finalize_model(model_rf,
parameters = best_hyperparameters # define
)8.3 Step 5: Fit final model to training data and assess accuracy
Once we are happy with our tuned random forest model and have chosen the best model specification stored in model_rf_tuned we can fit our workflow to the training data data_train again and also assess it’s accuracy again.
# Define final workflow
workflow_final <- workflow() %>%
add_recipe(recipe_rf) %>% # use standard recipe
add_model(model_rf_tuned) # use final model
# Fit final model
fit_final <- fit(workflow_final, data = data_train)
fit_final══ Workflow [trained] ══════════════════════════════════════════════════════════
Preprocessor: Recipe
Model: rand_forest()
── Preprocessor ────────────────────────────────────────────────────────────────
6 Recipe Steps
• step_filter_missing()
• step_impute_mean()
• step_unknown()
• step_nzv()
• step_novel()
• step_zv()
── Model ───────────────────────────────────────────────────────────────────────
Ranger result
Call:
ranger::ranger(x = maybe_data_frame(x), y = y, mtry = min_cols(~0L, x), num.trees = ~500, min.node.size = min_rows(~33L, x), importance = ~"permutation", num.threads = 1, verbose = FALSE, seed = sample.int(10^5, 1))
Type: Regression
Number of trees: 500
Sample size: 1417
Number of independent variables: 81
Mtry: 9
Target node size: 33
Variable importance mode: permutation
Splitrule: variance
OOB prediction error (MSE): 2.836466
R squared (OOB): 0.4093007 # Q: What do the values for `mtry` and `min_n` in the final model mean?
# Check accuracy in training data using MAE
augment(fit_final, new_data = data_train) %>%
mae(truth = life_satisfaction, estimate = .pred)# A tibble: 1 × 3
.metric .estimator .estimate
<chr> <chr> <dbl>
1 mae standard 0.939
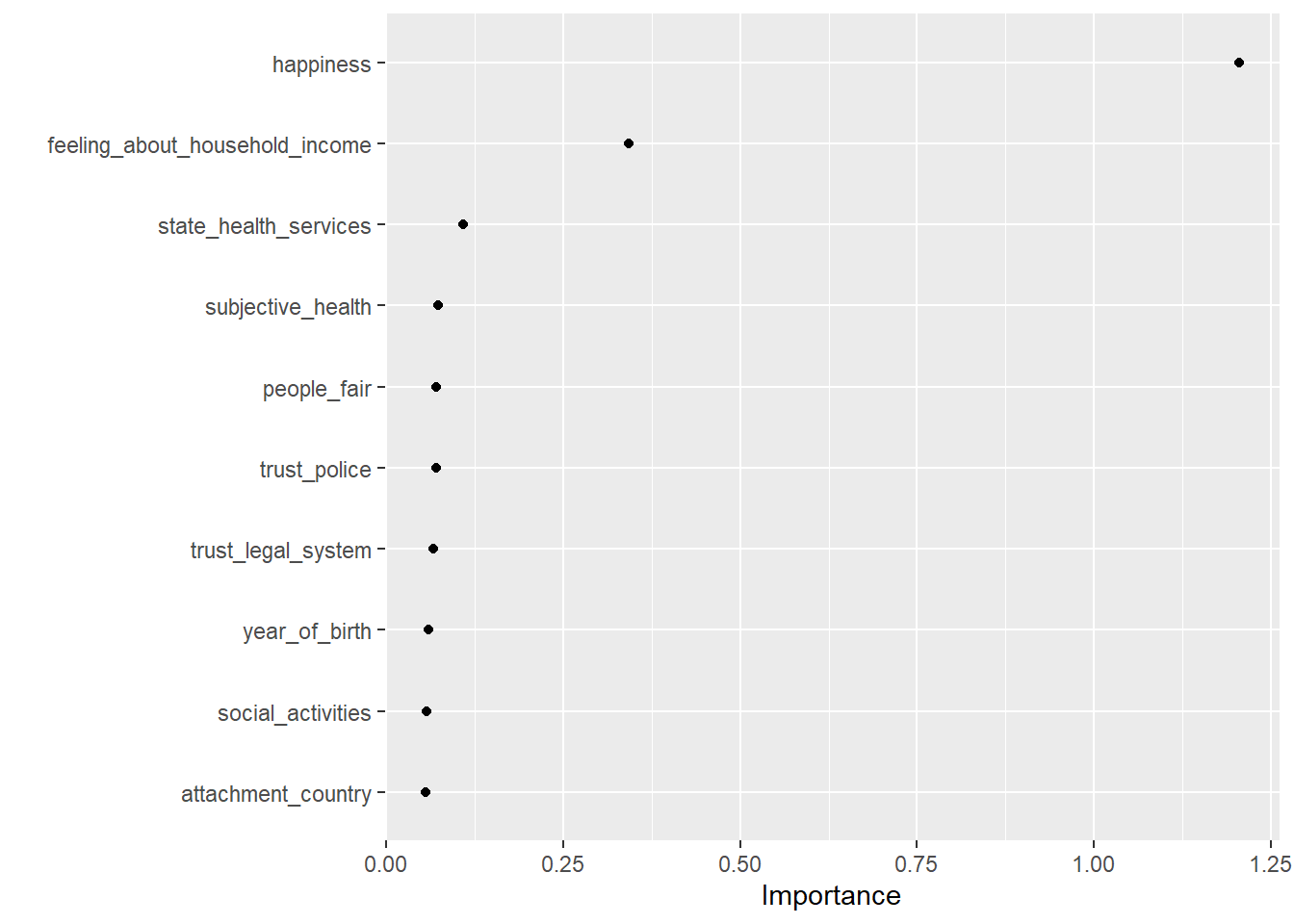
Now, that we have our final model we can also explore it assessing variable importance (i.e., which variables where the most relevant to find splits) using the vip package. We can use vi() and vip() to extract or extract+plot the variable importance of different predictors as shown in Table 1 and Figure 5. The vi() and vip() function does only like objects of class ranger, hence we have to directly access is in the layer object using fit_final$fit$fit$fit
# Visualize variable importance
# install.packages("vip")
library(vip)
fit_final$fit$fit %>%
vip::vi() %>%
kable()| Variable | Importance |
|---|---|
| happiness | 1.2044152 |
| feeling_about_household_income | 0.3430050 |
| state_health_services | 0.1090629 |
| subjective_health | 0.0734118 |
| people_fair | 0.0708766 |
| trust_police | 0.0706323 |
| trust_legal_system | 0.0666701 |
| year_of_birth | 0.0600826 |
| social_activities | 0.0567393 |
| attachment_country | 0.0557171 |
| age | 0.0492637 |
| attachment_europe | 0.0393355 |
| education | 0.0317052 |
| social_meetings | 0.0229720 |
| courts_equal_treatment | 0.0227331 |
| discrimination_not_applicable | 0.0210714 |
| respondent_overall_experience | 0.0208115 |
| maritalb | 0.0202021 |
| trust_people | 0.0186129 |
| daily_activities_hampered | 0.0181090 |
| discrimination_group_membership | 0.0169182 |
| climate_change_personal_responsibility | 0.0145519 |
| household_members | 0.0139224 |
| news_politics_minutes | 0.0131621 |
| internet_use_frequency | 0.0125505 |
| mnactic | 0.0122852 |
| people_helpful | 0.0106834 |
| value_security | 0.0078760 |
| value_wealth | 0.0070279 |
| political_interest | 0.0068330 |
| unemployment_over_3_months | 0.0067296 |
| religiousness | 0.0053654 |
| communication_feels_closer | 0.0052214 |
| discuss_intimate_matters | 0.0048764 |
| trade_union_membership | 0.0046252 |
| value_enjoying_life | 0.0041549 |
| doing7days_education | 0.0038439 |
| partner_paid_work_last_week | 0.0035884 |
| internet_access_home | 0.0032379 |
| domicile_description | 0.0031514 |
| crime_victim_last_5_years | 0.0030969 |
| value_understanding_others | 0.0030218 |
| value_proper_behavior | 0.0029897 |
| doing7days_retired | 0.0026514 |
| value_fun_pleasure | 0.0026425 |
| children_over_12_number | 0.0025662 |
| parents_alive | 0.0024654 |
| campaign_badge | 0.0024268 |
| value_environmental_care | 0.0024047 |
| female | 0.0023070 |
| value_success_recognition | 0.0022929 |
| internet_access_on_move | 0.0020805 |
| media_free_criticism_government | 0.0018617 |
| internet_access_work | 0.0017046 |
| signed_petition | 0.0016683 |
| born_in_country | 0.0015374 |
| partner_retired | 0.0015317 |
| father_born_in_country | 0.0013360 |
| internet_access_none | 0.0012998 |
| doing7days_paid_work | 0.0011085 |
| volunteered_charity | 0.0009080 |
| contacted_politician | 0.0008792 |
| mother_born_in_country | 0.0008783 |
| public_demonstration | 0.0008334 |
| value_equality | 0.0008043 |
| religious_service_attendance | 0.0007399 |
| ever_divorced | 0.0007148 |
| children_learns_obedience | 0.0003709 |
| value_trying_new_things | 0.0003284 |
| internet_access_other | 0.0001948 |
| government_protection_against_poverty | 0.0000334 |
| climate_change_administration | 0.0000132 |
| posted_politics_online | -0.0000147 |
| course_lecture_conference_attendance | -0.0001683 |
| value_modesty | -0.0006157 |
| citizenship_country | -0.0006667 |
| climate_change_worry | -0.0007541 |
| value_loyalty_to_friends | -0.0009043 |
| boycotted_products | -0.0009136 |
| value_freedom | -0.0046960 |
| value_helping_others | -0.0048345 |
8.4 Step 6: Fit final model to test data and assess accuracy
We then evaluate the accuracy of this model which is based on the training data using the test data data_test. We use augment() to obtain the predictions:
# A tibble: 355 × 347
.pred respondent_id life_satisfaction country unemployed_active unemployed
<dbl> <dbl> <dbl> <fct> <dbl> <dbl>
1 6.50 10011 7 FR 0 0
2 6.91 10092 8 FR 0 0
3 6.75 10096 6 FR 0 0
4 7.59 10210 8 FR 0 0
5 6.48 10341 9 FR 0 0
6 7.11 10405 8 FR 1 0
7 5.35 10412 2 FR 0 0
8 7.65 10447 7 FR 0 0
9 5.63 10506 0 FR 0 0
10 7.39 10521 4 FR 0 0
# ℹ 345 more rows
# ℹ 341 more variables: education <dbl>, news_politics_minutes <dbl>,
# internet_use_frequency <ord>, internet_use_time <dbl>, trust_people <dbl>,
# people_fair <dbl>, people_helpful <dbl>, political_interest <ord>,
# system_allows_say <ord>, active_role_politics <ord>,
# system_allows_influence <ord>, confident_participate_politics <ord>,
# trust_parliament <dbl>, trust_legal_system <dbl>, trust_police <dbl>, …
And can directly pipe the result into functions such as rsq(), rmse() and mae() to obtain the corresponding measures of accuracy in the test data data_test.
# A tibble: 1 × 3
.metric .estimator .estimate
<chr> <chr> <dbl>
1 rsq standard 0.486# A tibble: 1 × 3
.metric .estimator .estimate
<chr> <chr> <dbl>
1 rmse standard 1.84# A tibble: 1 × 3
.metric .estimator .estimate
<chr> <chr> <dbl>
1 mae standard 1.39The corresponding accuracy measures can now be compared to those of an untuned random forest model.
9 Lab: Tuning ridge regression
See earlier description here (right click and open in new tab).
We first import the data into R:
# Drop missings on outcome variable
data <- data %>%
drop_na(life_satisfaction) %>%
select(where(~mean(is.na(.)) < 0.1)) %>%
na.omit()
# Split the data into training and test data
data_split <- initial_split(data, prop = 0.80)
data_split # Inspect
# Extract the two datasets
data_train <- training(data_split)
data_test <- testing(data_split) # Do not touch until the end!
# Create resampled partitions
set.seed(345)
data_folds <- vfold_cv(data_train, v = 2) # V-fold/k-fold cross-validation
data_folds # data_folds now contains several resamples of our training data
# You can also try loo_cv(data_train) instead
# Define recipe
recipe_ridge <-
recipe(formula = life_satisfaction ~ ., data = data_train) %>%
update_role(respondent_id, new_role = "ID") %>%
# step_naomit(all_predictors()) %>% # we did this above
step_dummy(all_nominal_predictors()) %>%
step_zv(all_predictors()) %>% # remove any numeric variables that have zero variance.
step_normalize(all_numeric(), -all_outcomes()) # normalize (center and scale) the numeric variables. We need to do this because it’s important for lasso regularization
Then we specify the model. It’s similar to previous labs only that we set penalty = tune() to tell tune_grid() that the penalty parameter should be tuned.
Then we define a workflow called workflow1 that includes our recipe and model specification.
And we use grid_regular() to create a grid of evenly spaced parameter values. In it we use the penalty() function (dials package) to denote the parameter and set the range of the grid. Computation is fast so we can choose a fine-grained grid with 50 levels.
Then we can fit all our models using the resamples in data_folds using the tune_grid function.
And use autoplot to visualize the results.
Q: What does the graph show?
Yes, it visualizes how the performance metrics are impacted by our parameter choice of the regularization parameter, i.e, penalty \(\lambda\).
We can also collect the metrics:
Afterwards select_best() can be used to extract the best parameter value.
Finalize workflow, assess accuracy and extract predicted values
Finally, we can update our workflow with finalize_workflow() and set the penalty to best_penalty that we stored above, and fit the model on our training data.
We then evaluate the accuracy of this model (that is based on the training data) using the test data data_test. We use augment() to obtain the predictions:
And can directly pipe the result into functions such as rsq(), rmse() and mae() to obtain the corresponding measures of accuracy.
10 Lab: Tuning lasso
# Define the recipe
recipe2 <- recipe(life_satisfaction ~ ., data = data_train) %>%
step_zv(all_numeric_predictors()) %>% # remove predictors with zero variance
step_normalize(all_numeric_predictors()) %>% # normalize predictors
step_dummy(all_nominal_predictors())
# Specify the model
model2 <-
linear_reg(penalty = tune(), mixture = 1) %>%
set_mode("regression") %>%
set_engine("glmnet")
# Define the workflow
workflow2 <- workflow() %>%
add_recipe(recipe2) %>%
add_model(model2)
# Define the penalty grid
penalty_grid <- grid_regular(penalty(range = c(-2, 2)), levels = 50)
# Tune the model and visualize
tune_result <- tune_grid(
workflow2,
resamples = data_folds,
grid = penalty_grid
)
autoplot(tune_result)
# Select best penalty
best_penalty <- select_best(tune_result, metric = "rsq")
# Finalize workflow and fit model
workflow_final <- finalize_workflow(workflow2, best_penalty)
fit_final <- fit(workflow_final, data = data_train)
# Check accuracy in training data
augment(fit_final, new_data = data_train) %>%
mae(truth = life_satisfaction, estimate = .pred)
# Add predicted values to test data
augment(fit_final, new_data = data_test)
# Assess accuracy (RSQ)
augment(fit_final, new_data = data_test) %>%
rsq(truth = life_satisfaction, estimate = .pred)
# Assess accuracy (MAE)
augment(fit_final, new_data = data_test) %>%
mae(truth = life_satisfaction, estimate = .pred)11 Lab: Tuning XGBoost model
Below we use XGBoost to built a predictive model of life satisfaction. See here for another example. And Section 8.2.1 for and example of refining parameters after a first automated grid search.
set.seed(345)
# Extract data with missing outcome
data_missing_outcome <- data %>% filter(is.na(life_satisfaction))
dim(data_missing_outcome)
# Omit individuals with missing outcome from data
data <- data %>% drop_na(life_satisfaction) # ?drop_na
dim(data)
# STEP 2
# Split the data into training and test data
data_split <- initial_split(data, prop = 0.80)
data_split # Inspect
# Extract the two datasets
data_train <- training(data_split)
data_test <- testing(data_split) # Do not touch until the end!
# Create resampled partitions
data_folds <- vfold_cv(data_train, v = 5) # V-fold/k-fold cross-validation
data_folds # data_folds now contains several resamples of our training data
# Define recipe
recipe_xgb <-
recipe(formula = life_satisfaction ~ ., data = data_train) %>%
update_role(respondent_id, new_role = "ID") %>% # Declare ID variable
step_filter_missing(all_predictors(), threshold = 0.01) %>%
step_naomit(life_satisfaction, all_predictors()) %>% # better deal with missings beforehand
step_nzv(all_predictors(), freq_cut = 0, unique_cut = 0) %>% # remove variables with zero variances
#step_novel(all_nominal_predictors()) %>% # prepares data to handle previously unseen factor levels
step_unknown(all_nominal_predictors()) %>% # categorizes missing categorical data (NA's) as `unknown`
step_dummy(all_nominal_predictors())# %>% # dummy codes categorical variables
#step_zv(all_predictors()) %>% # remove vars with only single value
#step_normalize(all_predictors()) # normale predictors
# Inspect the recipe
recipe_xgb
# Check preprocessed data
data_preprocessed <- prep(recipe_xgb, data_train)$template
dim(data_preprocessed)
# Specify model with tuning
model_xgb <-
boost_tree(
trees = 500,
min_n = tune(), # Tune (see ?details_boost_tree_xgboost)
mtry = tune(),
stop_iter = tune(),
learn_rate = 0.01, # Choose higher value for speed (e.g., 0.3)
loss_reduction = tune(),
sample_size = tune()
) %>%
set_engine("xgboost") %>%
set_mode("regression")
# Specify workflow (with tuning)
workflow1 <- workflow() %>%
add_recipe(recipe_xgb) %>%
add_model(model_xgb)
## Step 4: Tune, evaluate the model using resampling and choose/explore the best model
# Specify to use parallel processing
doParallel::registerDoParallel()
tune_result <- tune_grid(
workflow1,
resamples = data_folds,
metrics = metric_set(mae, rmse, rsq), # Specify which metrics to calculate
grid = 5 # Choose grid points automatically; Pick lower value for speed
)
tune_result
# Show accuracy for different hyperparameters
tune_result %>%
collect_metrics()
# Visualize accuracy for different hyperparameters
tune_result %>%
collect_metrics() %>% # extract metrics
filter(.metric == "mae") %>% # keep mae only
select(mean, mtry:stop_iter) %>% # subset variables
pivot_longer(mtry:stop_iter, # convert to longer
values_to = "value",
names_to = "parameter"
) %>%
ggplot(aes(value, mean, color = parameter)) + # plot!
geom_point(show.legend = FALSE) +
facet_wrap(~parameter, scales = "free_x") +
labs(x = NULL, y = "MAE")
## Choose best model after tuning (for final fit)
# Find tuning parameter combination with best performance values
best_hyperparameters <- select_best(tune_result, metric = "mae")
best_hyperparameters
# Take list/tibble of tuning parameter values
# and update model_xgb with those values.
model_xgb_tuned <- finalize_model(model_xgb,
parameters = best_hyperparameters # define
)
## Step 5: Fit final model to training data and assess accuracy
# Define final workflow
workflow_final <- workflow() %>%
add_recipe(recipe_xgb) %>% # use standard recipe
add_model(model_xgb_tuned) # use final model
# Fit final model
fit_final <- fit(workflow_final, data = data_train)
fit_final
# Q: What do the values for `mtry` and `min_n` in the final model mean?
# Check accuracy in for full training data
metrics_combined <- metric_set(rsq, rmse, mae) # Set accuracy metrics
augment(fit_final, new_data = data_train) %>%
metrics_combined(truth = life_satisfaction, estimate = .pred)
# Visualize variable importance
# install.packages("vip")
library(vip)
fit_final$fit$fit %>%
vip::vi() %>%
kable()
fit_final$fit$fit %>%
vip(geom = "point")
## Step 6: Fit final model to test data and assess accuracy
augment(fit_final, new_data = data_test) %>%
metrics_combined(truth = life_satisfaction, estimate = .pred) References
Arnold, Christian, Luka Biedebach, Andreas Küpfer, and Marcel Neunhoeffer. 2024. “The Role of Hyperparameters in Machine Learning Models and How to Tune Them.” Political Science Research and Methods, 1–8.
Footnotes
published between 1 January 2016 and 20 October 2021 in some of the top journals of our discipline—the American Political Science Review (APSR), Political Analysis (PA), and Political Science Research and Methods (PSRM)↩︎
The
penaltyparameter refers to the amount of regularization applied to the model. Regularization is a technique used to prevent overfitting by adding apenaltyterm to the loss function, which discourages overly complex models. It helps in improving the model’s ability to generalize to unseen data by reducing the variance in the model’s predictions.
Lasso regression adds apenaltyterm to the loss function equal to the absolute value of the coefficients’ sum multiplied by a regularization parameter (lambdaoralpha). Thepenaltyparameter in tidymodels specifies the strength of this regularization term for Lasso regression. Higher values ofpenaltyresult in more regularization, leading to more coefficients being pushed towards zero, potentially resulting in a sparse model (some coefficients become exactly zero), which aids in feature selection.
Ridge regression, on the other hand, adds apenaltyterm to the loss function equal to the squared sum of the coefficients multiplied by a regularization parameter (lambdaoralpha). Similarly, thepenaltyparameter in tidymodels specifies the strength of this regularization term for Ridge regression. Higher values ofpenaltyresult in stronger regularization, but unlike Lasso, Ridge tends to shrink all coefficients towards zero proportionally without necessarily causing them to become zero, which helps in reducing multicollinearity.↩︎By adjusting the “tree_depth” parameter, you control the complexity of each individual decision tree in the XGBoost ensemble. Higher values allow the tree to capture more complex patterns in the data but may also increase the risk of overfitting. Conversely, lower values restrict the complexity of the tree, potentially improving generalization but may lead to underfitting if set too low.↩︎
treesdetermines the complexity and capacity of the model. More trees can potentially capture more complex patterns in the data but may also lead to overfitting if not controlled properly.↩︎learn_rateparameter, also known as the learning rate or eta in the context of XGBoost, is a crucial hyperparameter that influences the training process of gradient boosting algorithms, including XGBoost. The learning rate determines the step size or the rate at which the model updates its weights or parameters during the training process. It’s a scalar value that controls how much we are adjusting the weights of our network with respect to the loss gradient.↩︎The
loss_reductionparameter plays a role in controlling the construction of individual decision trees during the boosting process. Theloss_reductionparameter specifies the minimum amount of reduction in the loss function required to make a further partition on a leaf node of the decision tree. Essentially, it determines the threshold for splitting a node based on the improvement in the model’s performance.↩︎The
sample_sizeparameter specifies the proportion of observations sampled for each tree during the training process. Gradient boosting algorithms, including XGBoost, often use a technique called “bootstrapping” or “bagging” to train individual trees. In each iteration of training, a random subset of observations is sampled with replacement from the original dataset.↩︎The
stop_iterparameter is related to early stopping during the model training process. Early stopping is a technique used during the training of machine learning models to prevent overfitting and improve efficiency. Instead of training the model for a fixed number of iterations (or epochs), early stopping monitors a performance metric (e.g., validation loss) during training and stops training when the performance metric stops improving.↩︎